
Évaluation de YBA MAGAR — YBA dépasse les critères de référence du secteur et surpasse les principaux géants de la technologie
25 octobre 2025
Résumé
YBA MAGAR obtient un taux de réponse correct de 59,08 % sur le benchmark MuSique, ce qui correspond au modèle affiné de Microsoft et surpasse Salesforce, Google, Huawei et l'université de Pékin. Avec les meilleurs scores Exact Match (53,2 %) et F1 (69,5 %), MAGAR établit une nouvelle norme en matière de raisonnement augmenté par extraction pour l'IA d'entreprise.
Résumé
Nous présentons MAGAR (Multi-Agent Graph-Augmented RAG), un framework de génération augmenté par extraction qui combine la récupération basée sur des graphes avec une orchestration multi-agents pour soutenir un raisonnement contextuel robuste en plusieurs étapes sur les connaissances de l'entreprise. Pour évaluer la généralité de MAGAR pour le raisonnement à sauts multiples, nous l'avons comparé à MuSica, un ensemble de données public multi-documents et réponses à sauts multiples. Ce rapport présente les résultats d'évaluation tirés de notre matériel d'expérimentation, explique le protocole d'évaluation et fournit une annexe contenant des notes de reproductibilité. Tous les résultats numériques de ce rapport sont tirés du matériel d'évaluation fourni et n'ont pas été modifiés. Ces résultats confirment l'efficacité de MAGAR en matière de raisonnement augmenté par extraction et positionnent YBA parmi les leaders en matière de performances de réponse aux questions à sauts multiples.
Résultats de comparaison
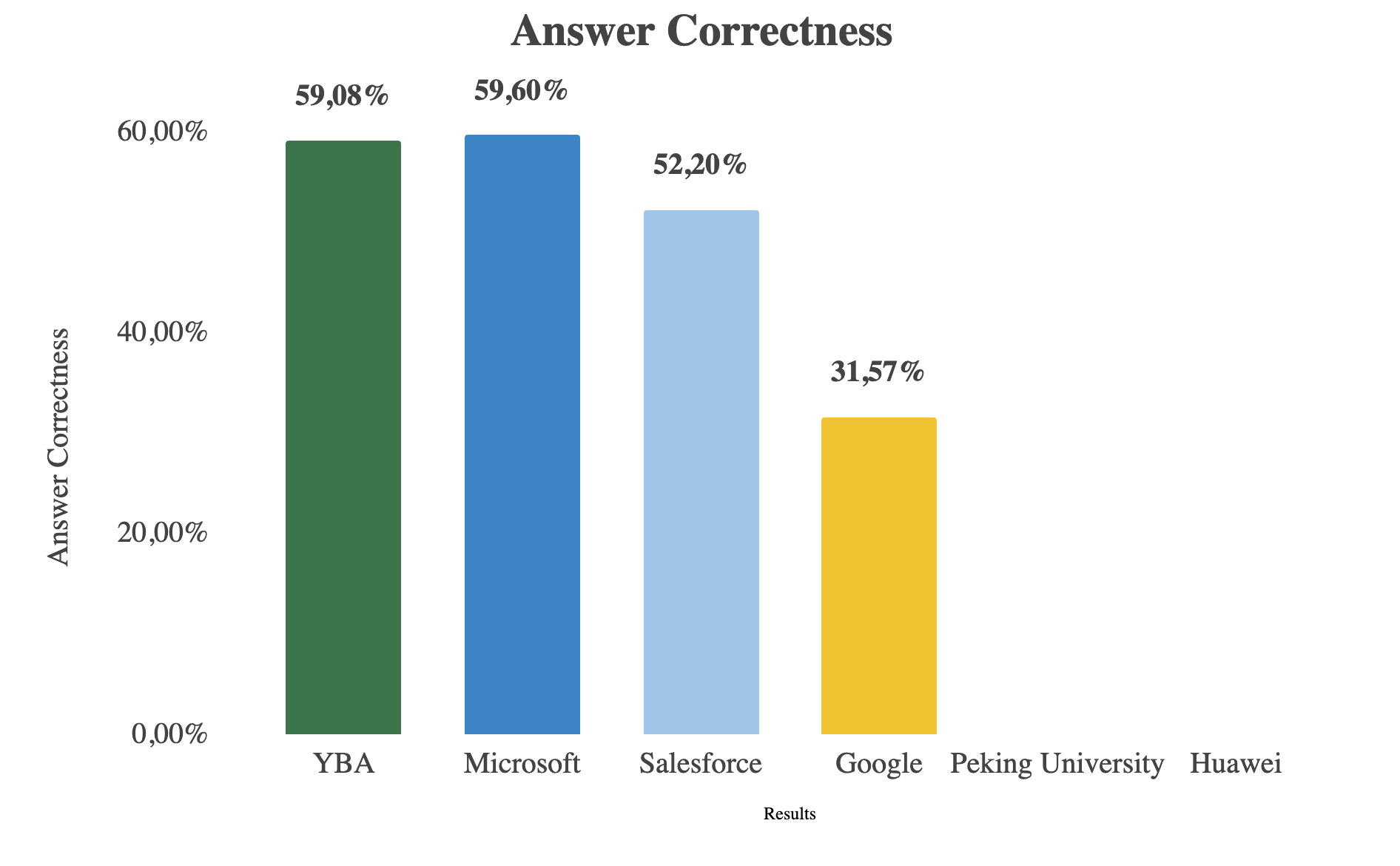
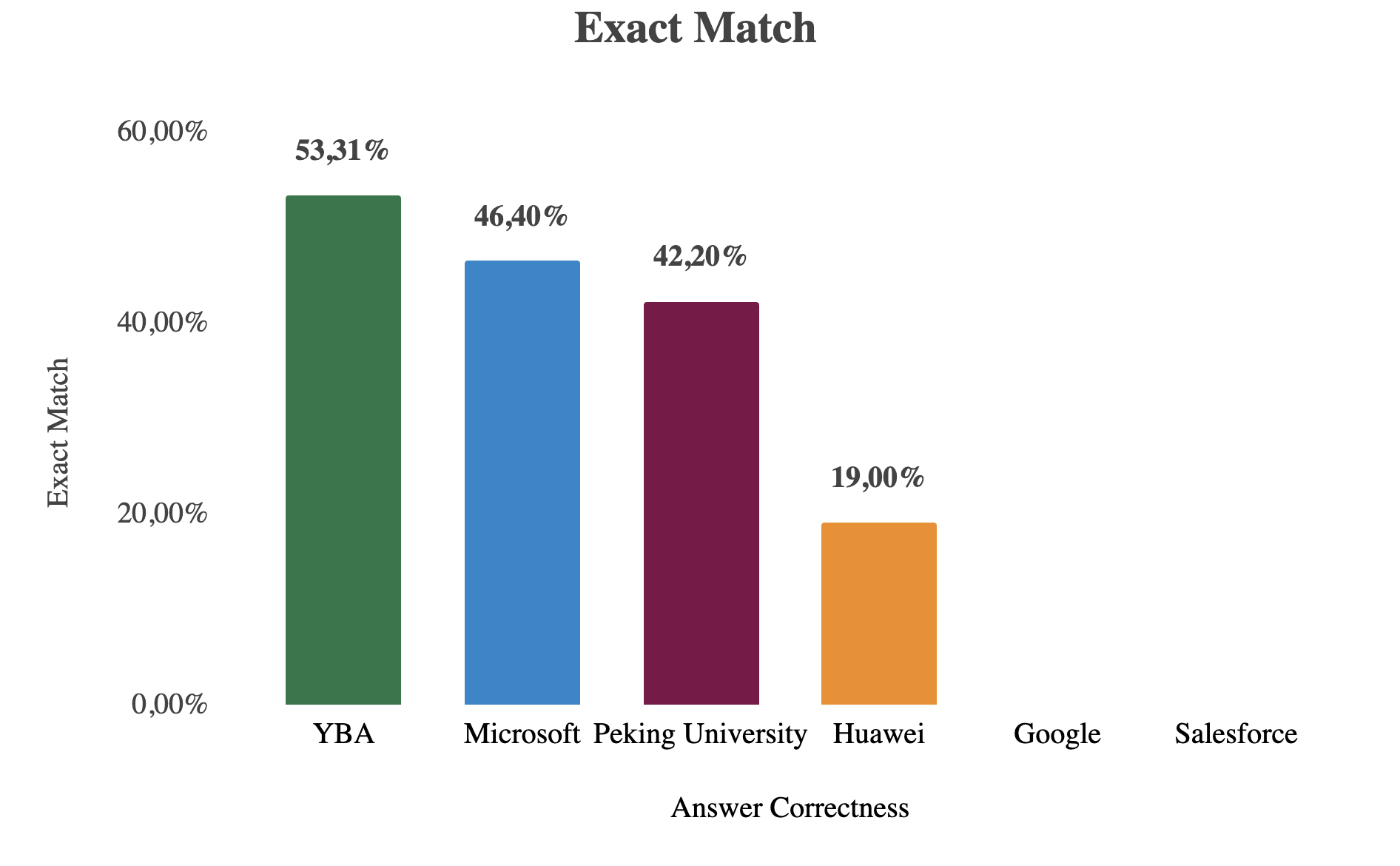
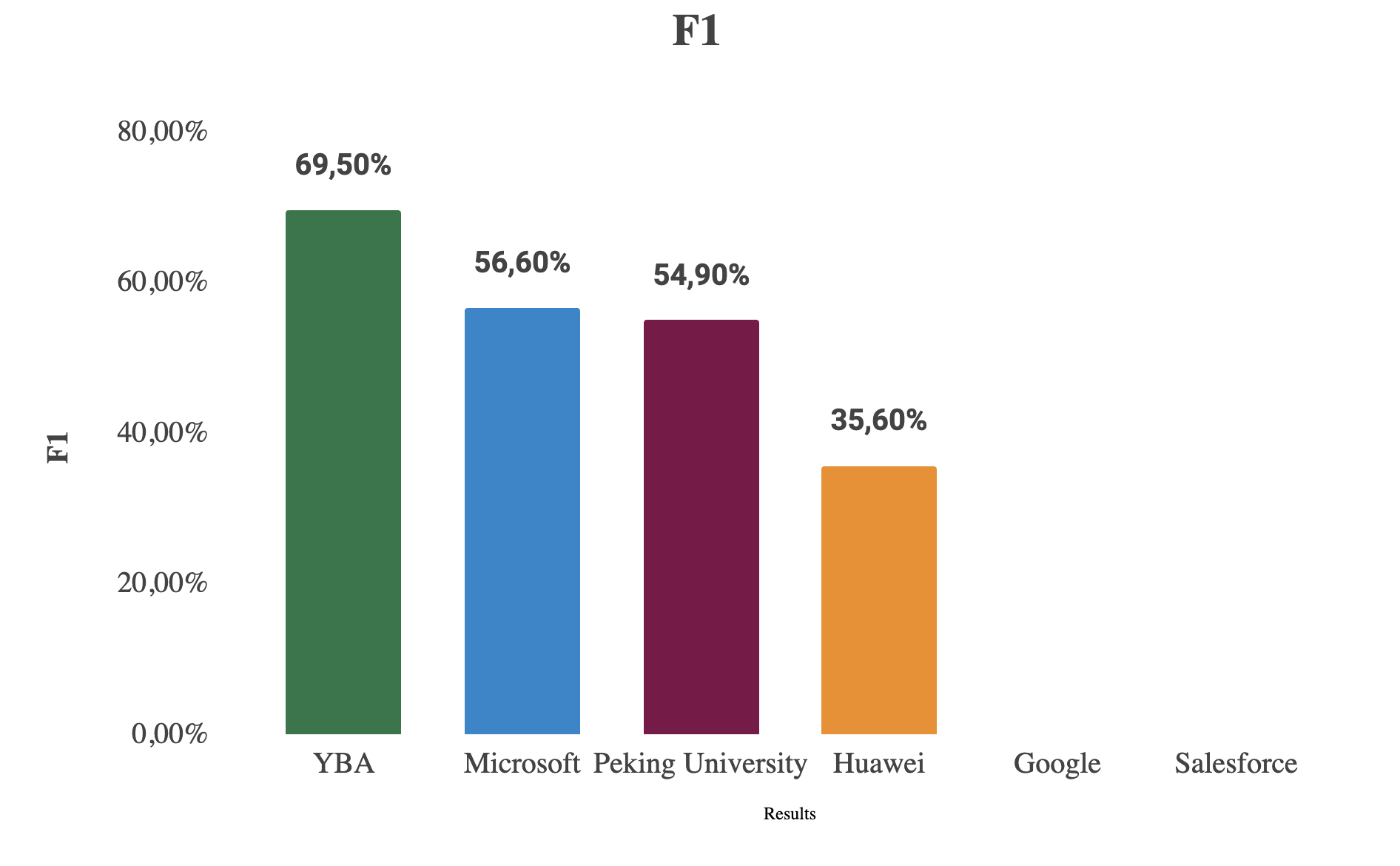
Chiffre : Comparaison des performances de YBA RAG (MAGAR) par rapport aux principaux systèmes In Context
À propos de YBA.ai
YBA.ai crée des agents contextuels qui automatisent le travail des connaissances pour les équipes chargées de la commercialisation. Notre technologie MAGAR (Multi-Agent Graph-Augmented RAG) associe la récupération basée sur des graphes à une orchestration multi-agents pour fournir un raisonnement robuste en plusieurs étapes et des réponses étayées par des preuves à partir des données et des bases de connaissances d'une entreprise.
Présentation
Les équipes GTM d'entreprise s'appuient de plus en plus sur des réponses précises et étayées par des preuves, tirées de la documentation interne (manuels, playbooks, documents sur les produits, notes CRM). Les questions à sauts multiples, c'est-à-dire celles qui nécessitent de relier les faits entre plusieurs documents et d'effectuer un raisonnement intermédiaire, constituent toujours un défi majeur pour les pipelines standard de récupération et de génération.
MAGAR a été développé pour résoudre ce problème : il augmente la récupération vectorielle grâce à une représentation graphique des connaissances et coordonne plusieurs agents spécialisés pour produire des réponses fondées avec provenance. MuSique est une référence publique pertinente pour l'assurance qualité multi-sauts ; nous l'avons utilisée pour valider la capacité de MAGAR à enchaîner les preuves et à produire des réponses correctes dans tous les documents.
Pourquoi MuSique ?
Cet ensemble de données est parfait pour valider MAGAR car il sonde rigoureusement les capacités de raisonnement complexes. Contrairement à une simple question de questions-réponses, une question MuSique nécessite que le système :
- Motif pour plusieurs documents : Les informations nécessaires à la réponse sont éparpillées et doivent être trouvées à différents endroits.
- Intégrer les preuves : Le système doit effectuer des étapes de raisonnement intermédiaires et relier des faits sémantiquement divers pour former une réponse finale et cohérente.
Ce besoin d'intégrer les preuves et de maintenir la séquence correspond directement aux principaux atouts de MAGAR : modéliser les relations entre les segments d'informations et préserver des séquences de tâches cohérentes grâce à sa récupération basée sur des graphiques.
Lien vers l'ensemble de données : https://arxiv.org/abs/2108.00573
Méthodologie d'évaluation
Pour garantir une évaluation objective et complète des performances de MAGAR, nous avons évalué le système à l'aide de mesures standard largement adoptées dans la recherche sur la génération retrieval-augmentée (RAG)
Métriques d'évaluation :
- Exactitude de la réponse : Mesure le degré d'exactitude et d'exhaustivité de la réponse générée par rapport à la réalité du terrain, à l'aide d'un juge basé sur le LLM pour un score compris entre 0 et 1.
- Correspondance exacte (EM) : Évalue si les mots clés ou les phrases de base apparaissent exactement dans le texte généré.
- Score en F1 : Équilibre précision et rappel pour évaluer à la fois l'exactitude et l'exhaustivité des réponses générées.
précision = jetons correspondants/jetons générés
rappel = jetons correspondants/jetons corrects
Score de F1 = 2 x (précision x rappel)/(précision + rappel)
- RAGAS (Cadre d'évaluation RAG) : Fournit une évaluation holistique basée sur le LLM de la qualité de la récupération et de la génération, en mesurant l'exactitude, la pertinence et l'exhaustivité des faits.
Résultats de nos tests
Nous avons testé MAGAR par rapport au kit de développement MuSique en utilisant deux scénarios pour garantir une validation complète et la confiance dans les résultats :
- Évaluation complète de l'ensemble de développeurs répondus : Nous avons utilisé l'ensemble complet de 1 127 questions pour évaluer de manière exhaustive les performances du framework sur l'ensemble des types de questions et des niveaux de difficulté.
- Évaluation aléatoire du sous-ensemble auquel il est possible de répondre : Nous avons également évalué le système sur un sous-ensemble aléatoire et plus petit de 500 questions auxquelles il est possible de répondre. Cela a permis de tester la robustesse de MAGAR et sa capacité à maintenir la cohérence des performances lorsqu'il s'agissait de traiter divers types de questions dans un échantillon restreint et représentatif.
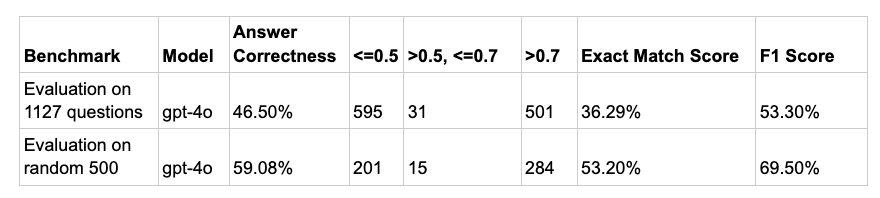
Les résultats de référence montrent que notre technologie a atteint Exactitude de la réponse de 46,50 % dans son intégralité 1 127 questions évaluation, avec Correspondance exacte de 36,29 % et un Score de F1 de 53,30 %. Sur le 500 questions aléatoires sous-ensemble, performances améliorées à 59,08 % Exactitude des réponses, 53,20 % Correspondance exacte, et Score de 69,50 % en F1, ce qui indique une précision et une exhaustivité accrues sur un ensemble d'évaluation plus restreint.
Analyse comparative par rapport aux travaux industriels et universitaires
Voici les détails des stratégies d'évaluation utilisées par d'autres
Microsoft - PIKE RAG :
- Statistiques publiées sur 01-01-2025
- Finetuned-LLM, y compris MuSique « train » split.
- Utilisez 500 questions aléatoires tirées du kit de développement MuSique
- Exactitude de la réponse = 59,60 %, score EM = 46,40 %, score F1 = 56,60 %
Google - RAG spéculatif :
- Publié le 11-07-2024.
- Un nombre indéterminé de questions a été utilisé pour l'évaluation à partir de l'ensemble de données MuSique.
- Je viens de le signaler Exactitude de la réponse = 31,57 %.
Salesforce - GPT-4o RAG + HyDE :
- Publié le 16-12-2024
- Utilise 500 questions sélectionnées au hasard à partir de la répartition des données de MuSique pour les développeurs.
- Signalé Exactitude de la réponse 52,20 %
Université de Pékin - HoPrag
- Publié le 18-02-2025
- Utilise 1 000 points de données provenant du kit de développement
- Score EM = 53,20 %, score F1 = 69,50 %
Huawei - GeAR :
- Publié le 24 décembre 2024
- Utilise 500 questions sélectionnées au hasard
- Score EM = 19,0, score F1 = 35,6
Le tableau suivant montre la comparaison de notre RAG par rapport aux autres
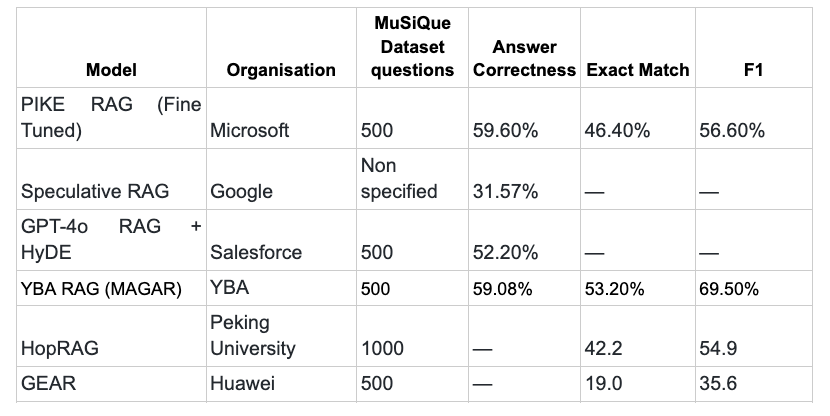
Analyse des performances et comparaison du secteur
En comparant YBA RAG (MAGAR) à d'autres systèmes de génération augmentés par récupération, nous constatons qu'il atteint l'une des meilleures performances globales sur le benchmark MuSique. Avec un exactitude des réponses de 59,08 %, le modèle de YBA fonctionne presque à égalité avec le PIKE RAG affiné de Microsoft (59,60 %), tandis que dépassant le GPT-4o RAG + HyDE de Salesforce (52,20 %), RAG spéculatif de Google (31,57 %), HoPrag de l'université de Pékin (42,2 % EM, 54,9 F1), et L'équipement de Huawei (19 % EM, 35,6 F1). Notamment, YBA MAGAR obtient le meilleur score Exact Match (53,2 %) et le meilleur score en F1 (69,5 %) parmi tous les modèles, démontrant une cohérence supérieure entre le contexte récupéré et les réponses générées. Cela indique que le mécanisme de récupération multi-agents de MAGAR améliore efficacement la précision des réponses et l'alignement contextuel.
Veuillez vous référer à la comparaison des résultats du graphique ci-dessus.
Remarque : Tous les résultats de l'analyse comparative sont dérivés de l'ensemble de données de développement MuSique et vérifiés à l'aide de mesures d'évaluation RAG standard.